
The Role of Automation in Data Processing: 2026 Guide

Automation in data processing is defined as the use of software systems, including ETL platforms, robotic process automation (RPA), and agentic AI, to execute repetitive data tasks with minimal human intervention. The role of automation in data processing has shifted from a convenience to a structural requirement: reporting time drops by up to 80% and pipeline development accelerates by 90–95% when automation replaces manual workflows. Data professionals who understand this shift gain a measurable advantage in throughput, accuracy, and strategic output.
How does automation improve efficiency and accuracy in data processing workflows?
Automated data workflows eliminate the manual bottlenecks that slow ingestion, cleaning, transformation, and monitoring. The gains are not marginal. Data professionals spend 60–80% of their time on preparation tasks alone, and AI can automate 40–70% of those weekly hours. That reclaimed time moves directly into analysis and decision support.
The accuracy gains are equally significant. Manual data entry and transformation introduce inconsistencies that compound across pipeline stages. Automated schema validation, type enforcement, and transformation rules apply the same logic to every record, every time. The result is a consistent, auditable output that manual processes cannot reliably replicate at scale.
Automation also changes the speed profile of the entire workflow. A pipeline that previously required a data engineer to write, test, and deploy transformation scripts over several days can now be generated and validated by an agentic AI system in hours. That compression does not just save time. It allows organizations to respond to new data requirements without queuing work against a backlog.
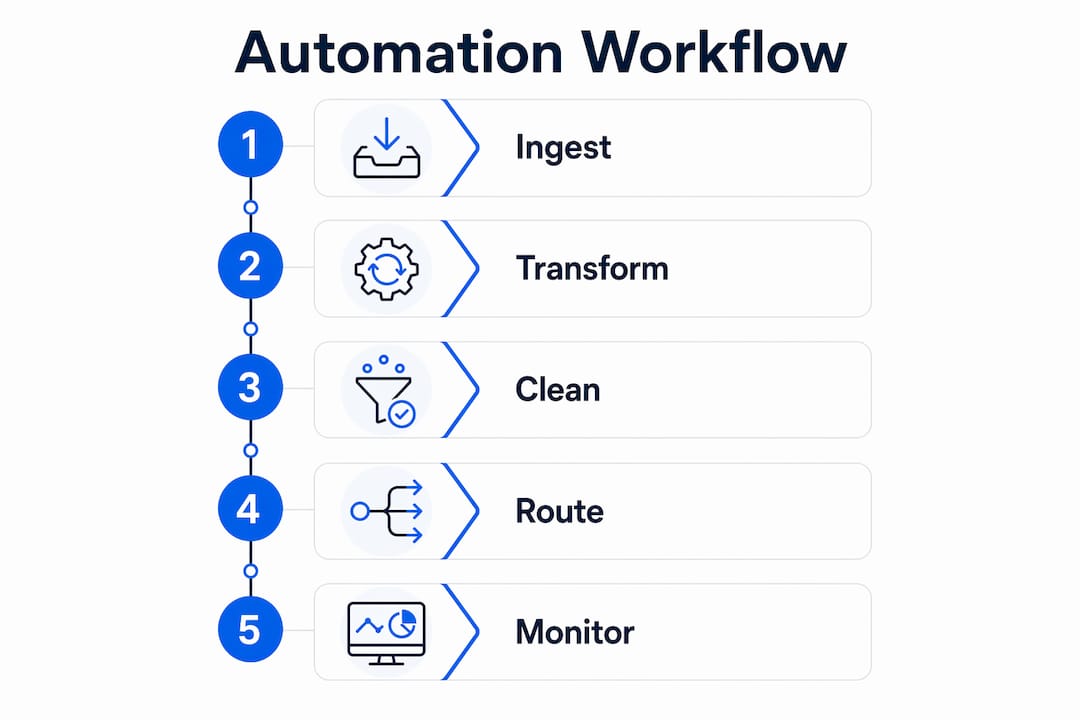
- Data ingestion: Automated connectors pull from APIs, databases, and flat files on defined schedules without manual intervention.
- Data cleaning: Rule-based and ML-driven routines flag nulls, duplicates, and outliers before data reaches downstream consumers.
- Transformation: ETL and ELT platforms apply business logic consistently across batches and streams.
- Monitoring: Anomaly detection tools alert teams to drift, schema changes, and volume drops in real time.
Pro Tip: Focus automation efforts on the middle layer first: transformation and routing. These tasks are high-volume, rule-bound, and low-judgment, which makes them the highest-return targets before touching ingestion edge cases or output interpretation.
What technologies and tools enable automation in modern data processing?
The technology stack for data processing automation spans four distinct categories, each addressing a different layer of the pipeline. Automation tools include RPA, AI-driven agents, cloud ETL platforms, NLP-enabled query translation, and real-time monitoring solutions. Each category handles a specific class of task, and mature organizations deploy all four in coordination.

Agentic AI systems represent the most significant recent development. These systems own the mechanical middle layer of data workflows, executing query translation, data transformation, anomaly detection, and enrichment autonomously. Humans define the questions at the edge and interpret the outputs. The agent handles everything in between.
NLP-enabled query translation is a particularly high-value capability for analytics teams. Analysts write questions in plain English, and the system translates them into SQL or API calls against the data warehouse. This removes the dependency on engineering resources for routine reporting and expands self-service access across the organization.
| Tool category | Primary function | Example use case |
|---|---|---|
| Cloud ETL platforms | Batch and stream data transformation | Scheduled pipeline from source database to warehouse |
| RPA | Rule-based task execution across systems | Automated report extraction from legacy applications |
| Agentic AI systems | Autonomous pipeline generation and management | Natural language to SQL query execution |
| Data observability tools | Anomaly detection and schema monitoring | Real-time alerts on volume drops or schema drift |
| NLP query interfaces | Self-service analytics translation | Business user querying warehouse without SQL knowledge |
Pro Tip: Before selecting a tool category, map your pipeline by task type. Mechanical, repeatable tasks belong to ETL and RPA. Judgment-adjacent tasks like anomaly triage belong to observability tools with human review. Mixing these categories creates governance gaps.
What are the challenges and best practices for automation in data processing?
Automation amplifies whatever exists in the pipeline before it. 90% of enterprise data is unstructured, and without ingestion-level quality controls, automated systems propagate errors at machine speed. The principle is direct: garbage in, garbage out, but faster and at greater scale.
The organizational risk is equally real. Consolidating data platforms and clarifying ownership is a prerequisite, not a follow-on step. Automation applied to fragmented, poorly governed data environments does not fix the dysfunction. It accelerates it. Teams that skip this step find themselves debugging automated pipelines that faithfully reproduce bad logic at high speed.
“Automation can move chaos faster. The first step is not selecting a tool. The first step is consolidating platforms and establishing who owns what.”
Effective automation requires controls embedded at the point of ingestion, not applied as a downstream patch. Quality controls at ingestion and data observability dashboards prevent bad data from cascading into reporting layers where it becomes invisible and trusted.
Best practices for sustainable automation include:
- Establish data governance before scaling. Define ownership, lineage, and access policies for every dataset before automating its movement.
- Embed schema validation at ingestion. Reject or quarantine records that fail type, range, or referential integrity checks before they enter the pipeline.
- Deploy observability dashboards. Monitor volume, freshness, and distribution metrics continuously. Treat anomalies as incidents, not background noise.
- Maintain human review at decision edges. Automated systems handle transformation and routing. Humans retain responsibility for interpreting outputs and acting on them.
- Audit automation logic regularly. Business rules change. Transformation scripts and agent instructions must be reviewed against current requirements on a defined schedule.
How is automation reshaping data roles and workflows?
Automation does not eliminate data roles. It redefines them. AI automates grunt work while human judgment remains critical for uncertainty, context, and decisions that require organizational knowledge. The practical effect is a shift in where skilled professionals spend their time.
The new role distribution follows a clear pattern:
- Data engineers move from writing and debugging pipeline scripts to designing agent frameworks, defining transformation rules, and governing the systems that execute them autonomously.
- Data analysts shift from manual data preparation and report building to formulating strategic questions, interpreting outputs, and communicating findings to decision-makers.
- Data stewards emerge as a critical function, validating AI-generated outputs, correcting misclassifications, and maintaining the reference data that automated systems depend on.
- Data governance leads take on expanded authority, setting the policies that constrain what automated systems can do and ensuring compliance with regulatory and organizational standards.
This redistribution produces measurable output gains. When engineers are no longer debugging pipeline failures and analysts are no longer cleaning spreadsheets, the same team produces more analysis per sprint. The throughput improvement is not a side effect of automation. It is the primary mechanism through which automation in data analysis delivers organizational value.
The human-machine collaboration model that emerges is architecturally clear. Automated systems own the middle layer: ingestion routing, transformation, enrichment, and scheduled reporting. Humans own the edges: defining the questions that matter and acting on the answers that come back. Organizations that try to automate the edges, asking machines to decide what questions to ask or what conclusions to draw, consistently underperform those that maintain that boundary.
Key takeaways
Automation in data processing delivers its highest returns when applied to mechanical middle-layer tasks within a well-governed data environment, with human oversight retained at decision edges.
| Point | Details |
|---|---|
| Efficiency gains are quantifiable | Reporting time drops up to 80% and pipeline development accelerates 90–95% with automation. |
| Middle-layer focus maximizes returns | Transformation, routing, and enrichment are the highest-value automation targets before edge tasks. |
| Governance must precede automation | Platform consolidation and ownership clarity prevent automation from amplifying existing data errors. |
| Human roles shift, not disappear | Engineers, analysts, and stewards move to oversight and strategic work as agents handle mechanical tasks. |
| Observability is non-negotiable | Real-time anomaly detection and schema monitoring are required infrastructure, not optional add-ons. |
Automation in practice: what I’ve learned after years of watching teams get it wrong
Most teams approach automation as a tool selection problem. They evaluate ETL platforms, compare agentic AI vendors, and build a shortlist before they have mapped their own pipeline. That sequence produces expensive mistakes.
The teams that extract the most value from automation share one habit: they consolidate before they automate. They reduce the number of platforms, establish clear data ownership, and document transformation logic before any agent touches a record. The automation then has something clean to work with.
The second pattern I see consistently is underinvestment in data stewardship after automation goes live. Automated systems generate outputs at a rate that exceeds human review capacity if stewardship is not explicitly resourced. The result is trusted reports built on quietly degraded data. The fix is not more automation. The fix is assigning people whose explicit job is to validate what the machines produce.
The third observation is about edge tasks. Automation handles transformation and routing well. It handles context and judgment poorly. Organizations that try to automate the interpretation of ambiguous signals, or the prioritization of competing business questions, consistently produce outputs that require expensive rework. Keep humans at the edges. Let the machines own the middle.
The future of data workflows is a hybrid architecture, and the professionals who thrive in it are those who understand both sides of the boundary.
— Nadeem
Explore R2nsoftware tools for data processing automation
R2nsoftware builds analytical software for data professionals who require precision at scale. PeakLab addresses the complex demands of peak fitting, baseline correction, and mass spectrometry analysis using advanced mathematical algorithms and statistical models. For teams working with automated signal processing and high-throughput data workflows, AutoSingal provides automated data processing and analytics capabilities designed to reduce manual intervention and improve reproducibility.
Both products are built for researchers and analysts in chromatography, spectroscopy, and chemometric modeling who need scientifically defensible results at the speed that modern data workflows demand. Visit R2nsoftware to explore product demos and technical documentation.
FAQ
What is the role of automation in data processing?
Automation in data processing executes repetitive tasks including ingestion, transformation, cleaning, and monitoring without manual intervention. Its primary role is to increase throughput, reduce errors, and free data professionals for strategic work.
How much time can automation save in data workflows?
Automation reduces reporting time by up to 80% and cuts pipeline development time by 90–95%. Data professionals currently spend 60–80% of their time on preparation tasks that AI can largely automate.
What are the biggest risks of automating data pipelines?
The chief risk is amplifying existing data quality problems at machine speed. Without ingestion-level quality controls, errors propagate downstream faster and at greater scale than manual processes would allow.
Does automation replace data engineers and analysts?
Automation shifts roles rather than eliminating them. Human judgment remains critical for contextual decisions, output interpretation, and governance. Engineers and analysts move to oversight, framework design, and strategic analysis.
What should organizations do before automating data workflows?
Consolidate platforms, establish data ownership, and embed schema validation at ingestion before scaling any automation. Clarifying ownership and governance is the prerequisite that determines whether automation improves or accelerates dysfunction.